Chào các bạn đến với bài thứ 16 trong series đục khoét và khám phá Javascript cũng như các thành phần của nó. Trong quá trình xác định và tìm hiểu các thành phần cốt lõi, tác giả cũng chia sẻ một số nguyên tắc mà họ đang dùng để xây dựng SessionStack, một ứng dụng Javascript hướng đến sự mạnh mẽ, hiệu năng cao và ổn định.
Khái quát
Lựa chọn cơ chế lưu trữ đúng đắn cho thiết bị lưu trữ ở local rất quan trọng khi thiết kế webapp. Một engine lưu trữ tốt sẽ đảm bảo thông tin của bạn được lưu chắc chắn, giảm băng thông và cải thiện sự phản hồi. Chiến lược lưu trữ bộ nhớ đệm phù hợp là thành phần cốt lõi cho phép trải nghiệm mobile web offline, càng ngày càng có nhiều người dùng cảm thấy rằng như đó là trải nghiệm mặc định phải có.
Trong chương này, chúng ta sẽ thảo luận về những API lưu trữ có sẵn & các service và cung cấp một số hướng dẫn làm thế nào để lựa chọn đúng loại cho webapp của bạn.
Data model (mô hình dữ liệu)
Mô hình lưu trữ dữ liệu xác định làm thế nào để dữ liệu được tổ chức nội bộ. Điều này ảnh hưởng toàn bộ thiết kế của webapp, định nghĩa sự cân bằng để làm cho webapp hoạt động hiệu quả nhưng vẫn giải quyết được vấn đề cần giải quyết. Giống như bất cứ thứ gì liên quan đến kỹ thuật, không tồn tại phương pháp nào "tốt hơn" và cũng không có giải pháp một-cho-tất-cả nào hết. Cùng xem qua 1 chút về một số data model mà ta có thể dùng:
- Kiểu cấu trúc: Dữ liệu được lưu trong các bảng kèm với các trường đã được định nghĩa, giống như các hệ quản trị cơ sở dữ liệu đặc trưng dựa trên SQL, chúng có tính linh hoạt và các câu truy vấn động. Một ví dụ nổi bật về kho dữ liệu kiểu cấu trúc trên trình duyệt chính là IndexedDB.
- key/value: kho dữ liệu key/value, và cả cơ sở dữ liệu NoSQL, cho phép lưu trữ và trích xuất dữ liệu không có cấu trúc được đánh index bằng 1 key duy nhất. Kho dữ liệu kiểu key/value giống như bảng băm (hash table) ở chỗ chúng cho phép truy cập liên tục vào các dữ liệu ẩn đã được đánh index. Một ví dụ điển hình cho kho dữ liệu key/value là Cache API trên trình duyệt và Apache Cassandra trên server.
- Byte Streams: mô hình đơn giản này lưu dữ liệu dưới dạng 1 biến độ dài, một chuỗi ẩn các byte, và nó để lại bất kỳ hình thức tổ chức nội bộ nào cho lớp ứng dụng. Mô hình này đặc biệt tốt cho các hệ thống tập tin (file) và các blob dữ liệu có tổ chức dạng phân cấp. Ví dụ điển hình của kho dữ liệu byte stream bao gồm những hệ thống file và các dịch vụ lưu trữ cloud.
Tính bền vững
Có thể phân tích các phương pháp lưu trữ cho webapp với sự mức độ ưu tiên cho timeframe hơn là dữ liệu nào cần được bền vững:
- Session Persistence (Bền vững phiên): dữ liệu trong mục này chỉ được giữ cố định miễn là một session của web hoặc một tab trên trình duyệt vẫn đang hoạt động. Ví dụ về cơ chế lưu trữ với phiên bền vững chính là Session Storage API
- Device Persistence (Bền vững thiết bị): dữ liệu trong mục này được giữ cố định xuyên suốt nhiều session và nhiều tab hoặc cửa sổ trình duyệt, trên 1 thiết bị cụ thể. Ví dụ: Cache API
- Global Persistence (Bền vững toàn cục): dữ liệu trong mục này được giữ cố định xuyên suốt các session & các thiết bị. Vì thế, đây là dạng mạnh mẽ nhất của bền vững dữ liệu. Nó không được lưu trữ trên chính thiết bị và điều đó nghĩa là bạn cần phải có 1 kiểu lưu trữ ở phía server. Chúng ta sẽ không thảo luận chi tiết về nó vì bài viết này chỉ tập trung vào lưu trữ dữ liệu trên thiết bị.
Bền vững dữ liệu trên trình duyệt
Ngày nay có rất ít các browser API cho phép bạn lưu trữ dữ liệu. Chúng ta sẽ tìm hiểu qua một vài thứ như thế và tạo 1 bản so sánh để có thể dễ dàng lựa chọn giải pháp phù hợp.
Tuy nhiên thì đầu tiên, có vài thứ bạn cần phải cân nhắc trước khi chọn làm thế nào để cố định dữ liệu. Dĩ nhiên thì thứ đầu tiên bạn cần phải hiểu kỹ chính là webapp của bạn được dùng như thế nào, sau đó còn có bảo trì và nâng cấp. Thậm chí nếu bạn có câu trả lời cho các câu hỏi đó, bạn cũng sẽ phải kết thúc với 1 số lựa chọn và chọn chúng. Vì thế nên dưới đây là 1 số thứ bạn nên xem qua:
- Trình duyệt hỗ trợ: bạn cần phải nhớ kỹ 1 sự thật là các API được xây dựng tốt & được chuẩn hóa có mức độ ưu ái cao hơn, bởi vì chúng hướng tới sự tồn tại lâu dài và được hỗ trợ rộng rãi. Những API đó cũng thường có tài liệu rộng hơn và cộng đồng developer hỗ trợ giàu kinh nghiệm hơn.
- Transactions (giao dịch): đôi khi transactions rất quan trọng đối với 1 tập hợp của các hoạt động lưu trữ tự động thành công hay thất bại. Các cơ sở dữ liệu theo truyền thống luôn hỗ trợ tính năng này sử dụng 1 mô hình transaction, những cập nhật liên quan được nhóm lại thành các đơn vị chuyên biệt.
- Sync/Async (đồng bộ/bất đồng bộ): một vài API lưu trữ thể hiện sự đồng bộ khi mà các request lưu trữ hoặc lấy dữ liệu sẽ chặn tiến trình đang hoạt động cho tới khi request được hoàn thành. Sử dụng API lưu trữ đồng bộ có thể chặn tiến trình chính và làm cho trải nghiệm UI trên webapp bị đông cứng không hoạt động. Nếu có thể, hãy dùng các API bất đồng bộ.
So sánh
Trong phần này, chúng ta sẽ so sánh các API hiện có dành cho web developer và so sánh chúng với các tiêu chí đã nói ở trên
| API | Mô hình dữ liệu (Data model) | Tính bền vững (persistence) | Trình duyệt hỗ trợ | Transactions | Sync/Async | | --------------------------- | ---------------------------- | --------------------------- | ------------------ | ------------ | ---------- | | File System (hệ thống file) | Byte stream | thiết bị | 52% | Không | Async | | Local Storage | key/value | thiết bị | 93% | Không | Sync | | Session Storage | key/value | session | 93% | Không | Sync | | Cookies | cấu trúc | thiết bị | 100% | Không | Sync | | Cache | key/value | thiết bị | 60% | Không | Async | | IndexedDB | hỗn hợp (hybrid) | thiết bị | 83% | Có | Async |
File System API (hệ thống file)

Với File System API, webapp có thể tạo, đọc, điều hướng và ghi vào 1 khu vực sandbox thuộc hệ thống local file của user.
API được chia nhỏ thành nhiều chủ đề:
- Đọc và sửa file: File/Blob, FileList, FileReader
- Tạo và ghi file: Blob(), FileWriter
- Các thư mục và truy cập hệ thống file: DirectoryReader, FileEntry/DirectoryEntry, LocalFileSystem
File System API không phải là 1 hệ thống API tiêu chuẩn. Bạn không nên dùng nó trên sản phẩm webapp production bởi vì nó sẽ không hoạt động với tất cả user. Có rất sự không tương thích lớn giữa các triển khai khác nhau và hành vi của chúng sẽ chắc chắn bị thay đổi trong tương lai.
FileSystem - interface của File & Directory Entries API được dùng để thể hiện 1 hệ thống file. Những object này có thể được lấy từ thuộc tính filesystem của bất kỳ entry thuộc hệ thống file nào. Một vài trình duyệt cung cấp thêm các API để tạo & quản lý các hệ thống file.
Interface này sẽ không cấp quyền cho bạn truy cập vào hệ thống file của user. Thay vào đó, bạn sẽ có 1 "ổ đĩa ảo" (virtual drive) bên trong sandbox của trình duyệt. Nếu bạn muốn truy cập vào hệ thống file của user, bạn cần phải gọi hỏi user bằng cách ví dụ như cài 1 Chrome extension.
Yêu cầu 1 hệ thống file
Một webapp có thể yêu cầu truy cập đến một hệ thống file sandbox bằng cách gọi: window.requestFileSystem():
// Lưu ý: Hệ thống file đã được đánh tiền tố tính đến Google Chrome 12.
window.requestFileSystem =
window.requestFileSystem || window.webkitRequestFileSystem;
window.requestFileSystem(type, size, successCallback, opt_errorCallback);Nếu bạn gọi hàm requestFileSystem() lần đầu tiên thì 1 vùng lưu trữ mới được tạo ra. Quan trọng hãy nhớ rằng hệ thống file này được gói gọn trong sandbox, nghĩa là 1 webapp không thể truy cập file của webapp khác.
Sau khi bạn có quyền truy cập vào hệ thống file, bạn có thể làm tất cả các hoạt động cơ bản với file & thư mục.
FileSystem là 1 lựa chọn lưu trữ khá khác biệt với các loại khác vì nó hướng đến thỏa mãn như cầu lưu trữ ở phía client trong những tình huống không dùng được cơ sở dữ liệu. Một cách tổng quát thì đó là những ứng dụng hoạt động với những cục blob nhị phân cỡ bự và/hoặc chia sẻ dữ liệu với các ứng dụng khác bên ngoài trình duyệt.
Dưới đây là những trường hợp có thể sử dụng FileSystem API:
- Tải lên (upload) liên tục: khi 1 file hay thư mục được chọn để upload, nó copy các file vào trong 1 vùng local sandbox và upload từng phần, từng phần.
- Video game, âm nhạc hoặc các app khác mà có nhiều tài nguyên media.
- Chỉnh sửa âm thanh/hình ảnh với truy cập offline hoặc là lưu đệm local để tăng tốc độ - những cục blob dữ liệu như thế thường rất lớn khi đọc-ghi.
- Xem video offline - cần phải download 1 lượng lớn file để xem sau hoặc seek + streaming hiệu quả.
- Ứng dụng Web Mail offline - download các file đính kèm và lưu chúng ở local.
Tình hình hỗ trợ của API:
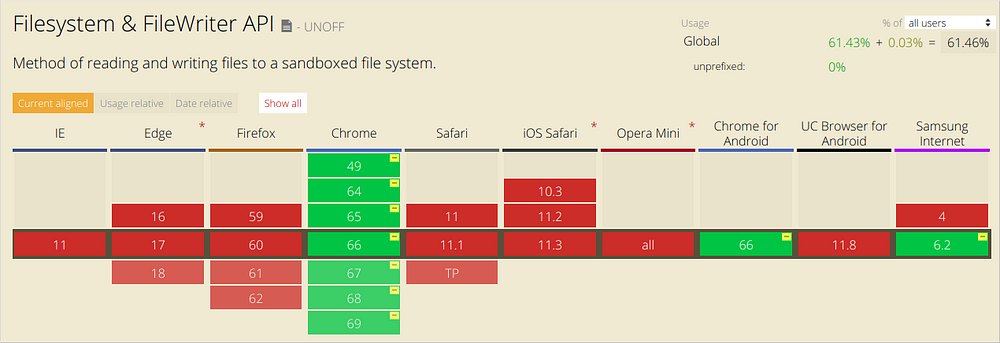
Local Storage

API localstorage cho phép bạn truy cập object Storage dành cho origin của Document. Dữ liệu lưu trữ xuyên suốt nhiều session trình duyệt. localstorage tương tự như sessionStorage, ngoại trừ việc dữ liệu lưu ở trong dataStorage không bị hết hạn, dữ liệu trong sessionStorage sẽ bị dọn dẹp khi session của trang kết thúc, tức là khi đóng tab trang đó.
Để ý rằng dữ liệu lưu trong localStorage hay sessionStorage là cụ thể cho origin của từng trang, bao gồm sự kết hợp của giao thức (protocol), host và cổng (port).
Tình hình hỗ trợ sáng sủa của nó:
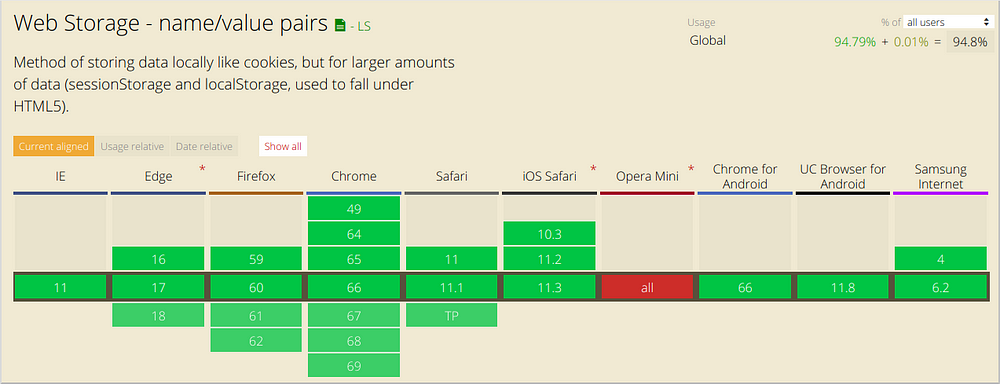
Session Storage

sessionStorage cho phép bạn truy cập vào 1 object Storage của session cho origin hiện tại. sessionStorage tương tự như localStorage, như đã giải thích ngắn gọn ở trên. Điểm khác biệt duy nhất là dữ liệu lưu trong localStorage không bị hết hạn, còn trong sessionStorage thì bị xóa khi session của trang kết thúc. Một session của trang tồn tại miễn là cửa sổ trình duyệt vẫn còn mở và tồn tại khi trang reload hoặc restore. Mở trang trong 1 tab mới hoặc cửa sổ mới sẽ tạo ra session mới, khác với cách hoạt động của session cookies.
Dữ liệu lưu trong sessionStorage hay localStorage là dành riêng cho origin của trang.
Tình hình hỗ trợ của sessionStorage:
Cookies

Một cookie (hay web cookie, cookie trình duyệt) là 1 cục dữ liệu nhỏ xíu mà server gửi đến trình duyệt của user. Trình duyệt có thể lưu nó và gửi ngược về cùng server đó trong request tiếp theo. Thông thường, nó được dùng để cho biết nếu 2 request đến từ cùng 1 trình duyệt - ví dụ: giữ cho user tiếp tục đăng nhập. Nó ghi nhớ thông tin trạng thái cho giao thức HTTP không trạng thái (stateless).
Cookies có 3 trường hợp dùng chính:
- Quản lý session: login, giỏ hàng online, lưu điểm game hay bất cứ thứ gì server cần nhớ.
- Cá nhân hóa (Personalization): các thiết đặt của người dùng, chủ để và những cài đặt khác.
- Theo dõi: ghi lại và phân tích hành vi của người dùng.
Cookies đã từng được dùng để lưu trữ tổng quát ở phía client. Như vậy vẫn hợp pháp vì lúc đó nó là giải pháp duy nhất để lưu trữ thông tin ở phía client, ngày nay thì người ta thường chọn các API lưu trữ hiện đại hơn. Cookies được gửi về với mỗi request nên có thể ảnh hưởng xấu đến hiệu năng (đặc biệt với các kết nối trên thiết bị di động).
Có 2 loại cookies:
- Cookie phiên (session cookies: Chúng bị xóa khi client tắt. Trình duyệt web có thể dùng khôi phục session để lấy lại gần hết session cookies, giống như là trình duyệt chưa bao giờ bị tắt vậy.
- Cookie dài hạn (permanent cookie): thay vì hết hạn khi người dùng tắt trình duyệt, permanent cookie hết hạn tại 1 ngày nhất định (Expires) hoặc là sau 1 khoảng thời gian nhất định (Max-Age).
Lưu ý rằng các thông tin bí mật và nhạy cảm không nên lưu hoặc vận chuyển với HTTP Cookies bởi vì rõ ràng toàn bộ cơ chế này vốn không an toàn.
Và rõ ràng là cookies hoạt động tốt với tất cả các trình duyệt.
Cache

Interface Cache cung cấp cơ chế lưu trữ cho cặp object Request/Response được lưu đệm. Lưu ý rằng interface Cache được dùng trong phạm vi window giống như workers. Bạn không phải dùng nó cùng với service worker mặc dù nó được định nghĩa trong thông tin của service worker.
Một origin có thể có nhiều object Cache (có tên cụ thể). Bạn có trách nhiệm triển khai code (ví dụ như trong ServiceWorker) để xử lý cập nhật cho Cache. Các item trong Cache không được cập nhật trừ khi được yêu cầu tường minh; chúng không hết hạn trừ khi bị xóa. Dùng hàm CacheStorage.open() để mở 1 object Cache với tên cụ thể và gọi bất kỳ phương thức Cache nào để bảo trì Cache.
Bạn cũng có trách nhiệm dọn dẹp định kỳ các cache entry. Mỗi trình duyệt có 1 giới hạn cứng với số lượng cache lưu trữ cấp cho 1 origin. Hạn mức sử dụng Cache ước tính tồn tại trong API StorageEstimate. Trình duyệt làm công việc tốt nhất của nó để quản lý dung lượng đĩa nhớ nhưng nó có thể xóa lưu trữ Cache của 1 origin. Đại khái là trình duyệt hoặc sẽ xóa tất cả dữ liệu của 1 origin hoặc không làm gì cả. Đảm bảo đánh phiên bản của cache bằng tên và chỉ dùng phiên bản cache nào mà code của bạn có thể sử dụng an toàn. Bạn có thể xem thêm bài Xóa cache cũ để hiểu thêm.
Interface CacheStorage thể hiện sự lưu trữ cho các object Cache
Interface:
- Cung cấp thư mục master của tất cả các cache có tên mà có thể truy xuất bởi ServiceWorker hoặc các loại worker khác hoặc phạm vi window (bạn không bị giới hạn chỉ sử dụng với service worker kể cả thông tin của Service Worker có định nghĩa như vậy).
- Duy trì khả năng ánh xạ (mapping) tên tương ứng với object Cache
Dùng phương thức CacheStorage.open() để lấy 1 instance của Cache
Dùng phương thức CacheStorage.match() để kiểm tra nếu 1 Request có phải là 1 key trong bất kỳ object Cache nào mà object CacheStorage theo dõi.
Bạn có thể truy cập CacheStorage thông qua thuộc tính toàn cục caches
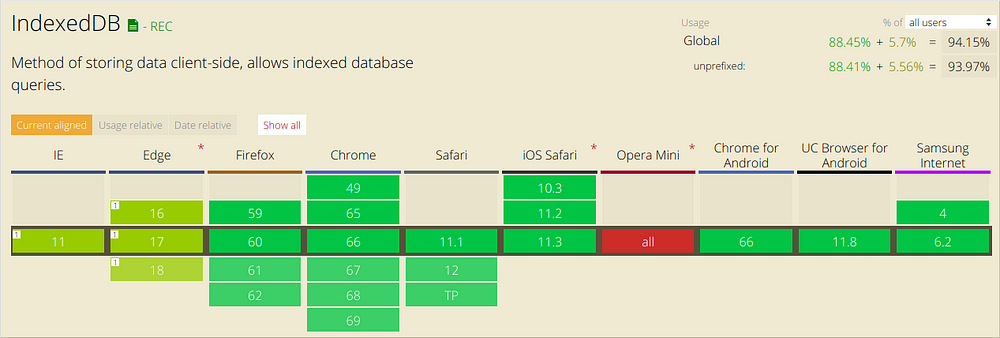
IndexedDB

IndexedDB là 1 cách để bạn lưu trữ dữ liệu một cách bền vững bên trong trình duyệt của người dùng. Bởi vì nó cho phép bạn tạo các webapp với khả năng viết câu truy vấn đa dạng bất kể tình trạng mạng. Những ứng dụng này có thể làm việc online & offline. IndexedDB có ích cho các ứng dụng cần lưu trữ 1 lượng lớn dữ liệu (ví dụ: danh sách các DVD cho mượn trong thư viện) và các ứng dụng không cần sự kết nối internet ổn định để hoạt động (ví dụ: ứng dụng mail, danh sách to-do, notepad).
Trong bài này, nó là cơ sở dữ liệu lưu trữ mà chúng ta sẽ thảo luận chi tiết hơn 1 chút bởi vì các API lưu trữ khác đều được hiểu biết khá rộng. Thêm nữa, IndexedDB càng ngày càng phổ biến với các webapp phức tạp ngày càng gia tăng.
Bên trong IndexedDB
IndexedDB cho phép bạn lưu trữ và lấy các object được lưu bằng cách dùng key. Tất cả thay đổi bạn thực hiện với cơ sở dữ liệu đều xảy ra trong phạm vi transaction. Giống như nhiều giải pháp lưu trữ web khác, IndexedDB bám sát nguyên tắc cùng origin (same-origin policy). Vì thế bạn có thể truy cập dữ liệu lưu trữ trong phạm vi 1 domain nhưng không thể truy cập dữ liệu của các domain khác.
IndexedDB là API bất đồng bộ (asynchronous) có thể sử dụng trong hầu hết các ngữ cảnh, bao gồm cả WebWorkers. Nó thường bao gồm cả 1 phiên bản đồng bộ (synchronous) nữa để dùng trong web worker nhưng đã bị xóa bỏ bởi vì cộng đồng web không có hứng thú với nó.
IndexedDB thường cạnh tranh với cơ sở dữ liệu WebSQL nhưng nó đã bị hủy bởi W3C. Trong khi cả 2 IndexedDB và WebSQL là các giải pháp lưu trữ, chúng lại không cung cấp cùng tính năng. CSDL WebSQL là 1 hệ truy cập CSDL quan hệ trong khi IndexedDB là hệ bảng đánh số (indexed table).
Đừng bắt đầu với IndexedDB nếu như bạn chỉ nghe nói hoặc giả định rằng nó tốt hơn các loại CSDL khác. Thay vì thế hãy đọc thật kỹ tài liệu của nó. Dưới đây là 1 vài ý tưởng cần thiết mà bạn cần phải biết:
- CSDL IndexedDB lưu theo cặp key-value: giá trị có thể là object cấu trúc phức tạp và key có thể là thuộc tính của những object đó. Bạn có thể tạo index dùng bất kỳ thuộc tính nào của object để dễ tìm kiếm cũng như khi cần sắp xếp. Key cũng có thể là object nhị phân.
- API IndexedDB đa phần là bất đồng bộ: API không đưa dữ liệu cho bạn bằng cách trả về giá trị. Thay vì thế nó truyền vào 1 hàm callback. Bạn không "lưu" 1 giá trị vào trong CSDL hoặc "lấy" nó ra theo nghĩa đồng bộ. Thay vào đó, bạn "yêu cầu" (request) một hành động trên CSDL. Một sự kiện thông báo cho bạn khi hành động hoàn thành và kiểu sự kiện bạn nhận được nếu như có hành động thành công hay thất bại. Không khác mấy so với cách hoạt động của XMLHttpRequest (hoặc là cả tá thứ khác về Javascript)
- IndexedDB dùng rất nhiều request: request là object nhận các sự kiện thành công hay thất bại như đã nói ở trên. Chúng có thuộc tính onsuccess và onerror cũng như readyState, result và errorCode sẽ cho bạn biết về trạng thái của request.
- IndexedDB hướng đối tượng: IndexedDB không phải CSDL quan hệ với các bảng thể hiện tập hợp hàng & cột. Điểm khác biệt cơ bản này ảnh hưởng đến giai đoạn thiết kế và xây dựng ứng dụng của bạn.
- IndexedDB không dùng ngôn ngữ truy vấn cấu trúc (SQL): nó dùng kiểu truy vấn trên index để tạo ra con trỏ, chính con trỏ này dùng để lặp xuyên suốt tập kết quả. Nếu bạn không quen với hệ thống NoSQL thì có thể xem thêm bài này trên Wikipedia
- IndexedDB dùng nguyên tắc cùng origin: một origin là domain, giao thức tầng ứng dụng và cổng (port) của URL của văn bản là nơi mà code được thực thi. Mỗi origin có 1 tập các CSDL riêng của nó. Mỗi CSDL có 1 cái tên định danh nó trong origin.
Giới hạn của IndexedDB
IndexedDB được thiết kế để dùng với hầu hết các tình huống cần lưu trữ ở phía client. Nó không được thiết kế cho 1 vài trường hợp dưới đây:
- Sắp xếp toàn cầu (Internationalized sorting): không phải tất cả ngôn ngữ đều sắp xếp array theo cùng 1 cách, vì thế mà Internationalized sorting không được hỗ trợ. CSDL không thể lưu dữ liệu theo 1 thứ tự toàn cầu cụ thể, bạn có thể tự tay sắp xếp dữ liệu đọc từ CSDL ra.
- Đồng bộ hóa: API không được thiết kế để thực hiện đồng bộ hóa với CSDL ở phía server. Bạn phải viết code riêng để đồng bộ CSDL IndexedDB ở client với CSDL ở server.
- Tìm kiếm toàn văn bản (Full text searching ): API không cung cấp giải pháp tương tự như LIKE trong SQL.
Thêm vào đó, hãy cẩn thận trình duyệt có thể xóa CSDL trong những trường hợp sau đây:
- User yêu cầu xóa: nhiều trình duyệt có cài đặt cho phép user xóa tất cả dữ liệu lưu trữ cho 1 website, bao gồm cả cookies, bookmarks, mật khẩu được lưu và dữ liệu IndexedDB.
- Trình duyệt đang chạy chế độ riêng tư: một vài trình duyệt có chế độ riêng tư như private browsing (Firefox) hay incognito (Chrome). Tại cuối session, trình duyệt sẽ xóa toàn bộ CSDL.
- Ổ cứng hoặc giới hạn cho phép bị đầy
- Dữ liệu bị hỏng
Các trường hợp chính xác và khả năng của trình duyệt thay đổi theo thời gian, nhưng nguyên lý chung của các nhà phát triển trình duyệt là tạo ra nỗ lực tốt nhất để lưu giữ dữ liệu khi có thể.
Lựa chọn API lưu trữ
Như đã đề cập ở trên, sẽ tốt hơn nếu chọn các API được hỗ trợ rộng rãi trong nhiều trình duyệt và cung cấp mô hình gọi bất đồng bộ nhằm nâng tối đa khả năng phản hồi của UI. Như 1 cách tự nhiên, ngữ cảnh như thế này sẽ dẫn đến các lựa chọn công nghệ:
- Với lưu trữ offline, dùng Cache API. API này tồn tại trong các trình duyệt hỗ trợ công nghệ Service Worker, cần thiết để xây dựng app offline.
- Để lưu trữ trạng thái của ứng dụng và các dữ liệu do người dùng tạo ra, sử dụng IndexedDB. Nó cho phép user làm việc offline trên nhiều trình duyệt hơn so với những trình duyệt chỉ hỗ trợ Cache API.
SessionStack sử dụng các API lưu trữ khác nhau. Ví dụ, thư viện tích hợp vào trong webapp của khách hàng dùng cả cookies & session storage. Lý do là thư viện đó cần thu thập các dữ liệu chẳng hạn như các sự kiện, thay đổi trên DOM, dữ liệu mạng, biệt lệ, thông tin debug, vân vân, rồi sau đó gửi về server. Họ thu thập dữ liệu như vậy từ session của người dùng nhưng họ cần 1 cách chính xác để xác định khi nào session của user bắt đầu và kết thúc.
Họ cân nhắc 1 session sẽ là toàn bộ chu kỳ sử dụng webapp từ lúc bắt đầu, bao gồm cả xem trang và điều hướng cho đến khi user đóng trình duyệt hay tab và không quay trở lại trong vài phút, phần này họ dùng 1 sự kết hợp của session storage & logic ở phía server. Còn gì nữa nào, họ cho phép bạn xác định từng người dùng cuối để có thể cung cấp cho bạn dữ liệu người dùng trên mỗi session. Họ dựa vào cookies để làm việc này (giống như các công cụ giám sát/phân tích).
Trong ứng dụng của họ, bạn có thể xem (xem theo yêu cầu hoặc thời gian thực) những sự kiện đã thu tập dưới dạng video được tái tạo lại cách mà user gặp phải các vấn đều, họ sử dụng chủ yếu là cookies bởi vì serivce RESTful của họ về cơ bản thì cần authentication token để authenticate, authorize và xác nhận request.